
Very often it is necessary to drop a lot of records into the database at one time. If the files are large and we want to make the best use of our equipment, it is worth using the Spring Batch. If, in addition to the project itself, you want to learn more about the structure and functions of Spring Batch, then I invite you to this [TODO] guide.
USE CASE:
As a user, I want to use the API to upload many records into the database from CSV file.
TECH STACK:
Java / Spring-Boot / PostgreSQL / Spring Batch
In order to correctly send the file, you will need to properly format this data. The data will be sent for the request using a POST request. Although it is possible to import the contents of the file in plain text, it is very inefficient – if the file contains information about a large number of records, the request body will be difficult to build. To avoid this, we will use a special data format – the uploaded file will be encoded in Base64 format.
In the case of complex applications, consisting of both frontend and backend parts, this string can be transformed while passing data from one layer to another. In order to simplify our problem – we will do the coding of the CSV file content on an external website. Here, for example, I recommend this website – (https://www.base64encode.org/)
Burnside,Raquela,Moscow,Garek,1167223970
Jobi,Ivett,Punta Arenas,Gusella,4567223970
Melan,Tatiania,Samara,Ader,5567223970
Cloris,Albertina,Accra,Drisko,2556722291
Riva,Kirbee,Belfast,Therine,5567223245
Gombach,Dennie,Wuhan,Maiah,5655639829QnVybnNpZGUsUmFxdWVsYSxNb3Njb3csR2FyZWssMTE2NzIyMzk3MApKb2JpLEl2ZXR0LFB1bnRhIEFyZW5hcyxHdXNlbGxhLDQ1NjcyMjM5NzAKTWVsYW4sVGF0aWFuaWEsU2FtYXJhLEFkZXIsNTU2NzIyMzk3MApDbG9yaXMsQWxiZXJ0aW5hLEFjY3JhLERyaXNrbywyNTU2NzIyMjkxClJpdmEsS2lyYmVlLEJlbGZhc3QsVGhlcmluZSw1NTY3MjIzMjQ1CkdvbWJhY2gsRGVubmllLFd1aGFuLE1haWFoLDU2NTU2Mzk4Mjk=To start, let’s create a new project from Spring Initializr with all following dependencies: spring batch, jdbc and psql. In this example, I’ll be using PostgreSQL for this example, but generally any JDBC supported database will do.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>The configuration and parameters of our database can be specified in our application in various ways. Recently, the most popular ways are to define access data in a properties or yaml file. In this example, I used the first option, so the database access data is defined in the default application.properties file. If you do not have a database running yet, I recommend creating it locally using for example the docker image (in case of any problems, you can always restart the container and even recreate it without side effects).
spring.datasource.driver-class-name=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://0.0.0.0:5438/batch_db
spring.datasource.username=postgres
spring.datasource.password=postgres
spring.batch.initialize-schema=always Once we have our database configured, we can create our application code. At the beginning of the java code implementation, we need to define the object on which we will operate.
@Getter
@Setter
@Entity
@Table(name = "tracks")
@ToString
@AllArgsConstructor
@Builder
@NoArgsConstructor
public class Track {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private String id;
private String title;
private String artist;
private String version;
private String url;
private String code;
}
If our entity agrees with the table that we previously defined in the database, it’s high time to start implementing batch processes. You have to create a main configuration class in which all magic tricks will take place. In my case it will be the EncodedCsvToDatabaseConfig class Firstly, we need to add @EnableBatchProcessing annotation, which is needed only once within the whole application. This annotation provides us the full service and infrastructure that enables job processes in batch.
@Configuration
@EnableBatchProcessing
public class EncodedCsvToDatabaseJobConfig {
public final JobBuilderFactory jobBuilderFactory;
public final StepBuilderFactory stepBuilderFactory;
public final DataSource dataSource;
public final MainDatabaseConfiguration mainDatabaseConfiguration;
private final JdbcTemplate jdbcTemplate;
public EncodedCsvToDatabaseJobConfig(JobBuilderFactory jobBuilderFactory,
StepBuilderFactory stepBuilderFactory,
DataSource dataSource,
MainDatabaseConfiguration mainDatabaseConfiguration,
JdbcTemplate jdbcTemplate) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
this.dataSource = dataSource;
this.mainDatabaseConfiguration = mainDatabaseConfiguration;
this.jdbcTemplate = jdbcTemplate;
}
// code implementation
}When we have a configuration class created, we can add two important classes inside it, which will be responsible for the factories of the Job and Step instances. Thanks to them, we can now easily create new instances of these classes. What’s more, we added also DataSource to be used with the JobRepository and JdbcTemplate which simplifies the use of JDBC and helps to avoid common errors. In addition, a separate configuration MainDatabaseConfiguration class for database management has been created. All of the above dependencies could be added using the popular @Autowire annotation, but for a long time Spring’s creators have suggested using constructors instead of this annotation.
@Configuration
@PropertySource({"classpath:main-database.properties"})
@EnableJpaRepositories(
basePackages = {
"com.oskarro.batcher.environment.main.model",
"com.oskarro.batcher.environment.main.repo"
},
entityManagerFactoryRef = "mainEntityManager",
transactionManagerRef = "mainTransactionManager")
public class MainDatabaseConfiguration {
private final Environment env;
public MainDatabaseConfiguration(Environment env) {
this.env = env;
}
@Bean
@Primary
public DataSource mainDataSource() {
// TODO
}
@Bean
@Primary
public LocalContainerEntityManagerFactoryBean mainEntityManager() {
// TODO
}
@Bean
@Primary
public PlatformTransactionManager mainTransactionManager() {
// TODO
}
}The MainDatabaseConfiguration class is responsible for the configuration of database connections and settings for all queries and transactions. Metoda mainDataSource() is a factory for connections to the physical data source that this DataSource object represents. Environment extracts the configuration data. This interface represents the environment in which the current application is running.environment variables are retrieved with the values previously specified in the application.properties file. These environment variables are retrieved with the values previously specified in the application.properties file.
@Bean
@Primary
public DataSource mainDataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName(Objects.requireNonNull(env.getProperty("datasource.driver-class-name")));
dataSource.setUrl(Objects.requireNonNull(env.getProperty("datasource.url")));
dataSource.setUsername(Objects.requireNonNull(env.getProperty("datasource.username")));
dataSource.setPassword(Objects.requireNonNull(env.getProperty("datasource.password")));
return dataSource;
}Next, the function to call LocalContainerEntityManagerFactoryBean is defined. This factory bean creates a special JPA EntityManagerFactory according to JPA’s standard container bootstrap contract. In my opition this is the most powerful way to set up a shared EntityManagerFactory in a Spring application context. Thanks to the previously defined DataSource instance, we can now implement it inside the EnityManager. There are also added settings needed for the operation with hibernate.
@Bean
@Primary
public LocalContainerEntityManagerFactoryBean mainEntityManager() {
LocalContainerEntityManagerFactoryBean em = new LocalContainerEntityManagerFactoryBean();
em.setDataSource(mainDataSource());
em.setPackagesToScan("com.oskarro.batcher.environment.main.model");
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
em.setJpaVendorAdapter(vendorAdapter);
HashMap<String, Object> properties = new HashMap<>();
properties.put("hibernate.hbm2ddl.auto", env.getProperty("hibernate.hbm2ddl.auto"));
properties.put("hibernate.dialect", env.getProperty("hibernate.dialect"));
em.setJpaPropertyMap(properties);
return em;
}The final part of the database configuration is the additional TransactionManager. For this the main interface in Spring’s imperative transaction infrastructure was used.
@Bean
@Primary
public PlatformTransactionManager mainTransactionManager() {
JpaTransactionManager transactionManager = new JpaTransactionManager();
transactionManager.setEntityManagerFactory(mainEntityManager().getObject());
return transactionManager;
}I’d like to note that the @Primary annotation has been added for each bean. Are you wondering why? This will come in handy when your application is getting bigger – if there are several beans of the same type, Spring doesn’t know what to choose. This annotation helps with this and declares the priority of instance selection in Spring.
Once we have our database configured, we can create our application code for Job in batch process. Before we start writing code, it is worth mentioning the structure of these types of processes. Batch job is a collection of states and transitions from one step to the next. Generally, steps are the most popular way of these states used in Spring batch so I’ll focus on them for now. Using the case of the importing records to database as an our example – we will prepare one chunk-based step consisting of three main parts:
- ItemReader – could be to load tracks received from request body
- ItemProcessor – would apply and transform all lines to the objects
- ItemWriter – would insert all new tracks to database
Our job represents the overall process of inserting tracks to the database. When a job is executed a big bunch of components interact to provide the resiliency that Spring Batch provides. To understand the problem – I suggest you take a look at the graphic below:
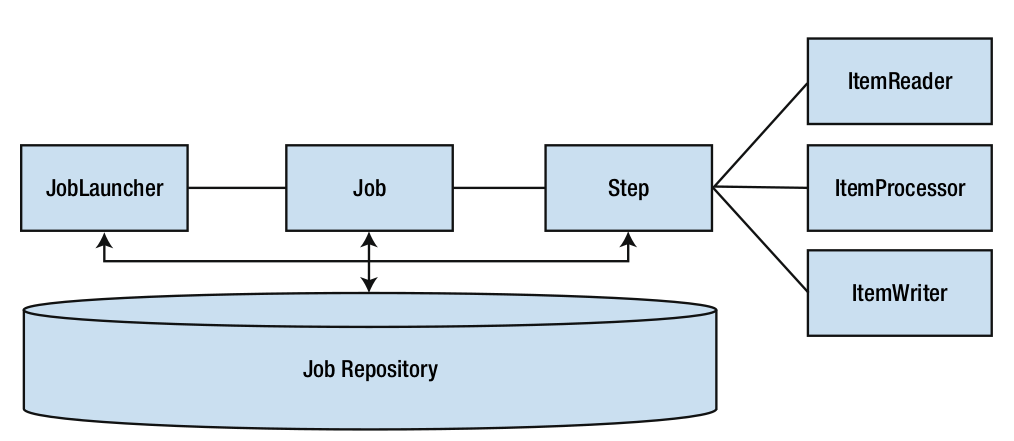
JobLauncher component is responsible for execution of Job. Once a job is running, this job executes all provided steps. When each step is executed, it goes through list of items read in by the ItemReader, processes them and finally write results. When a Job or at least one Step is completed, the related execution is updated in the repository with the final status.
After a short explanation, we can move on to action. We have to start with the lowest abstraction. Each our chunk will be executed within its own transaction allowing Spring Batch to restart after the last successful transaction after a failure. So, the first loop is with the IteamReader, which reads all the lines to be processed within this chunk into memory. In our case, encodedCsvReader method takes the decoded value of our request, converts it into a byte array and splits this content into separate records.
@Bean
@StepScope
public FlatFileItemReader<Track> encodedCsvReader(@Value("#{jobParameters['decodedContent']}") String decodedContent) {
FlatFileItemReader<Track> reader = new FlatFileItemReader<>();
reader.setResource(new ByteArrayResource(decodedContent.getBytes(StandardCharsets.UTF_8)));
reader.setLineMapper(new DefaultLineMapper<>() {{
setLineTokenizer(new DelimitedLineTokenizer() {{
setNames("title", "artist", "version", "url", "code");
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(Track.class);
}});
}});
return reader;
}The second batch process loop is with ItemProcessor (it is optional). If the ItemProcessor is implemented, the all items that were read will be looped over – so each of them being passed through the ItemProcessor. The proxy class does nothing special. I added it to show you how to use it. It only translates the value read earlier to a new object, prints logs to the terminal and returns a record ready for writing.
@Bean
ItemProcessor<Track, Track> encodedCsvProcessor() {
return new TrackProcessor();
}public class TrackProcessor implements ItemProcessor<Track, Track> {
private static final Logger log = LoggerFactory.getLogger(TrackProcessor.class);
@Override
public Track process(final Track track) {
final String id = track.getId();
final String title = track.getTitle();
final String artist = track.getArtist();
final String version = track.getVersion();
final String url = track.getUrl();
final String code = track.getCode();
final Track transformedTrack = new Track(id, title, artist, version, url, code);
log.info("Converting (" + track + ") into (" + transformedTrack + ")");
return transformedTrack;
}
}At the end of the action, all records are passed in a single request to ItemWriter.
@Bean
public JdbcBatchItemWriter<Track> encodedCsvWriter() {
JdbcBatchItemWriter<Track> csvTrackWriter = new JdbcBatchItemWriter<>();
csvTrackWriter.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
csvTrackWriter.setSql(
"INSERT INTO tracks (id, title, artist, version, url, code) " +
"VALUES (nextval('track_id_seq'), :title, :artist, :version, :url, :code)");
csvTrackWriter.setDataSource(mainDatabaseConfiguration.mainDataSource());
return csvTrackWriter;
}When we have all the operations within one step ready, we can combine them.
@Bean
public Step encodedCsvToDatabaseStep() {
return stepBuilderFactory
.get("encodedCsvToDatabaseStep")
.<Track, Track>chunk(5)
.reader(encodedCsvReader(WILL_BE_INJECTED))
.processor(encodedCsvProcessor())
.writer(encodedCsvWriter())
.build();
}Then we are invoke this step inside our main job.
@Bean(name = "encodedCsvToDatabaseJob")
public Job encodedCsvToDatabaseJob() {
return jobBuilderFactory
.get("encodedCsvToDatabaseJob")
.incrementer(new DailyJobTimestamper())
.listener(JobListenerFactoryBean.getListener(
new JobCompletionNotificationListener(
jdbcTemplate, "Decoding file content and saving tracks to database")))
.flow(encodedCsvToDatabaseStep())
.end()
.build();
}For each instance, I have added the @Bean annotation so that these objects can be extracted anytime and anywhere in the code. With our factory wired in, I define a bean-named encoded
The implementation of our batch part is ready. Now we can try to make it available in the controller in such a way that the end user can use it. Before adding the API method in the controller, we need to fetch the job and jobLauncher beans to the controller class.
@RestController
@RequestMapping("/api")
public class BatchController {
JobLauncher jobLauncher;
public BatchController(JobLauncher jobLauncher) {
this.jobLauncher = jobLauncher;
}
@RequestMapping(value = "/batch", method = RequestMethod.POST)
@ResponseBody
public String saveTracksFromRequestBodyToDatabase(@RequestBody String content) {
System.out.println("==== Encoded content ====\n" + content);
Base64 base64 = new Base64();
String decodedString = new String(base64.decode(content));
System.out.println("==== Decoded content ====\n" + decodedString);
try {
JobParameters jobParameters = new JobParametersBuilder()
.addString("decodedContent", decodedString)
.addDate("currentDate", new Date())
.toJobParameters();
JobExecution jobExecution = jobLauncher.run(encodedCsvToDatabaseJob, jobParameters);
} catch (JobExecutionAlreadyRunningException | JobRestartException
| JobInstanceAlreadyCompleteException | JobParametersInvalidException e) {
e.printStackTrace();
}
return "Request with batch has been sent";
}
}If we have already implemented the entire application, we can check and evaluate the final effects.

After sending a request you should see the following logs in terminal:
2021-09-05 13:14:11.592 INFO 185290 --- [nio-8080-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2021-09-05 13:14:11.592 INFO 185290 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2021-09-05 13:14:11.594 INFO 185290 --- [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 2 ms
==== Encoded content ====
QnVybnNpZGUsUmFxdWVsYSxNb3Njb3csR2FyZWssMTE2NzIyMzk3MApKb2JpLEl2ZXR0LFB1bnRhIEFyZW5hcyxHdXNlbGxhLDQ1NjcyMjM5NzAKTWVsYW4sVGF0aWFuaWEsU2FtYXJhLEFkZXIsNTU2NzIyMzk3MApDbG9yaXMsQWxiZXJ0aW5hLEFjY3JhLERyaXNrbywyNTU2NzIyMjkxClJpdmEsS2lyYmVlLEJlbGZhc3QsVGhlcmluZSw1NTY3MjIzMjQ1CkdvbWJhY2gsRGVubmllLFd1aGFuLE1haWFoLDU2NTU2Mzk4Mjk=
==== Decoded content ====
Burnside,Raquela,Moscow,Garek,1167223970
Jobi,Ivett,Punta Arenas,Gusella,4567223970
Melan,Tatiania,Samara,Ader,5567223970
Cloris,Albertina,Accra,Drisko,2556722291
Riva,Kirbee,Belfast,Therine,5567223245
Gombach,Dennie,Wuhan,Maiah,5655639829
2021-09-05 13:14:11.653 INFO 185290 --- [nio-8080-exec-1] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=encodedCsvToDatabaseJob]] launched with the following parameters: [{decodedContent=Burnside,Raquela,Moscow,Garek,1167223970
Jobi,Ivett,Punta Arenas,Gusella,4567223970
Melan,Tatiania,Samara,Ader,5567223970
Cloris,Albertina,Accra,Drisko,2556722291
Riva,Kirbee,Belfast,Therine,5567223245
Gombach,Dennie,Wuhan,Maiah,5655639829, currentDate=1630840451633}]
2021-09-05 13:14:11.661 INFO 185290 --- [nio-8080-exec-1] .b.b.c.JobCompletionNotificationListener : ============ JOB STARTED [Decoding file content and saving tracks to database] ============
encodedCsvToDatabaseJob is beginning execution
2021-09-05 13:14:11.696 INFO 185290 --- [nio-8080-exec-1] o.s.batch.core.job.SimpleStepHandler : Executing step: [encodedCsvToDatabaseStep]
2021-09-05 13:14:11.760 INFO 185290 --- [nio-8080-exec-1] c.o.b.b.csvToDatabase.TrackProcessor : Converting (Track(id=null, title=Burnside, artist=Raquela, version=Moscow, url=Garek, code=1167223970)) into (Track(id=null, title=Burnside, artist=Raquela, version=Moscow, url=Garek, code=1167223970))
2021-09-05 13:14:11.761 INFO 185290 --- [nio-8080-exec-1] c.o.b.b.csvToDatabase.TrackProcessor : Converting (Track(id=null, title=Jobi, artist=Ivett, version=Punta Arenas, url=Gusella, code=4567223970)) into (Track(id=null, title=Jobi, artist=Ivett, version=Punta Arenas, url=Gusella, code=4567223970))
2021-09-05 13:14:11.761 INFO 185290 --- [nio-8080-exec-1] c.o.b.b.csvToDatabase.TrackProcessor : Converting (Track(id=null, title=Melan, artist=Tatiania, version=Samara, url=Ader, code=5567223970)) into (Track(id=null, title=Melan, artist=Tatiania, version=Samara, url=Ader, code=5567223970))
2021-09-05 13:14:11.761 INFO 185290 --- [nio-8080-exec-1] c.o.b.b.csvToDatabase.TrackProcessor : Converting (Track(id=null, title=Cloris, artist=Albertina, version=Accra, url=Drisko, code=2556722291)) into (Track(id=null, title=Cloris, artist=Albertina, version=Accra, url=Drisko, code=2556722291))
2021-09-05 13:14:11.761 INFO 185290 --- [nio-8080-exec-1] c.o.b.b.csvToDatabase.TrackProcessor : Converting (Track(id=null, title=Riva, artist=Kirbee, version=Belfast, url=Therine, code=5567223245)) into (Track(id=null, title=Riva, artist=Kirbee, version=Belfast, url=Therine, code=5567223245))
2021-09-05 13:14:11.777 INFO 185290 --- [nio-8080-exec-1] c.o.b.b.csvToDatabase.TrackProcessor : Converting (Track(id=null, title=Gombach, artist=Dennie, version=Wuhan, url=Maiah, code=5655639829)) into (Track(id=null, title=Gombach, artist=Dennie, version=Wuhan, url=Maiah, code=5655639829))
2021-09-05 13:14:11.792 INFO 185290 --- [nio-8080-exec-1] o.s.batch.core.step.AbstractStep : Step: [encodedCsvToDatabaseStep] executed in 96ms
2021-09-05 13:14:11.808 INFO 185290 --- [nio-8080-exec-1] .b.b.c.JobCompletionNotificationListener : ============ JOB FINISHED [Decoding file content and saving tracks to database] ============
=== Procedure encodedCsvToDatabaseJob has completed with the status COMPLETED === 2021-09-05 13:14:11.817 INFO 185290 --- [nio-8080-exec-1] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=encodedCsvToDatabaseJob]] completed with the following parameters: [{decodedContent=Burnside,Raquela,Moscow,Garek,1167223970
Jobi,Ivett,Punta Arenas,Gusella,4567223970
Melan,Tatiania,Samara,Ader,5567223970
Cloris,Albertina,Accra,Drisko,2556722291
Riva,Kirbee,Belfast,Therine,5567223245
Gombach,Dennie,Wuhan,Maiah,5655639829, currentDate=1630840451633}] and the following status: [COMPLETED] in 155ms
Finally, let’s check the contents of our database using following command:
SELECT * FROM tracks;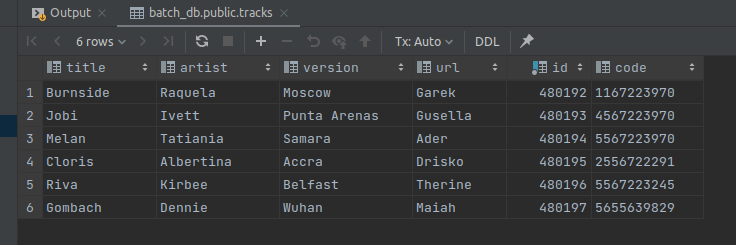
If you have any questions or observations – write in the comment below. Any opinion is appreciated. Thanks for your attention!
7 czerwca, 2022, 9:56 am
Bardzo ciekawy blog, rzeczowy i wyważony. Od dzisiaj zaglądam regularnie. Pozdrowienia 🙂