
I’ve seen a lot of tutorials in Internet related to Spring Batch tool, but most of them was too simply. I know that these guides can be great for basic understanding the main concept of that technology, but it is not enough to make an application that will find use in real life. In this tutorial I will show you how to build a complete application using Spring Batch.
Technologies that we will use during the implementation of the app:
- Java 11
- Spring 5
- Spring Batch
- PostgreSQL
The batch job you develop in this chapter is all about a fictional banking space called SoccerBank. Inside this organization, all virtual transactions between individual clubs (e.g. fees for transfers) will be carried out. At the end of each month, the clubs receive a composite statement that lists all their accounts, all of the transactions that occurred over the past month, the total amount that was credited to their account, total amount that was debited from their account, and their current balance.
The main task will be quite complex – it will consist of four separate operations:
- Importing all club updates (and their accounts),
- this step import one CSV file which contains a records with information about club accounts updates
- these changes will be applied to the Postgres database
- Importing transactions
- all executed transactions will be provided inside XML file
- content of that XML files will be imported to the database
- Applying procedures and transactions
- after entering the transaction into the database, the changes will be reflected in individual accounts
- Generating final statements
- for each club one file will be created that has all information about account balance and list of executed transactions
Setting Up a New Project
I’m using IDEA (JetBrains) so I’ll walk you through those steps. We will use a very comfortable tools – Spring Initializr.
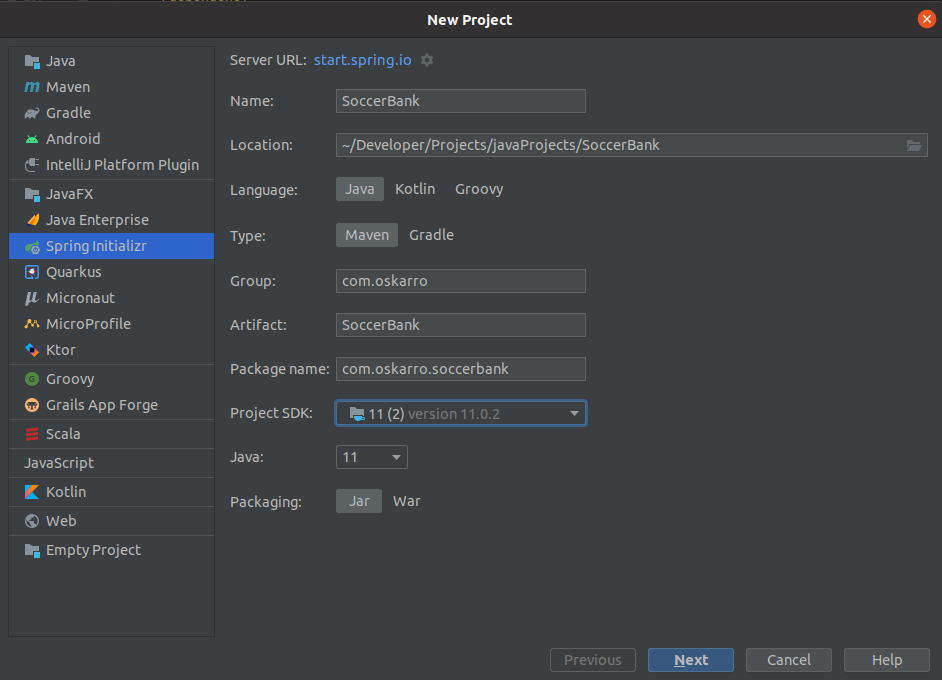
This application will be built using Maven. You can fill in the group id, artifact id and package name. I’ve also selected JAR for the packaging type, so the Spring Boot plugin will generate jar files for us. As you can see, Java version has been selected twice, because the first one was what your IDE will use to build and run the project in, while the second one is what the Maven POM will be configured to compile to.
After going to the next window, we will be able to choose all the necessary dependencies. The minimum that we will definitely use is what you can see in the attached photo. If you prefer to use a different database or add some magic effects – you are free to add what you need to your project.
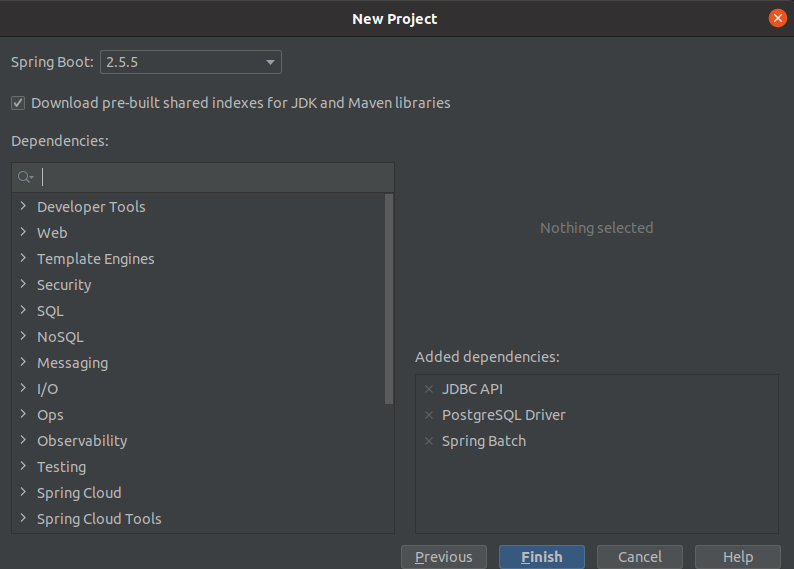
Of course, you can also add selected dependencies directly to the pom.xml file, but for a project that is configured from scratch, using the graphical interface is more convenient. After completing the initialization of the project, we should receive a ready project with the basic configuration.
Now you need to add an annotation responsible for enabling batch processes support -> @EnableBatchProcessing
Before we start implementing the main program, we will prepare a database schema on which we will work. As mentioned before, I chose the postgresql database which I embedded in the Docker container. If you chose something else, go to the next step. I will describe my way here (someone may find it useful). In order to follow next steps you need to have installed Docker on your PC. The instructions for most popular operating systems can be found here: Ubuntu, Windows, Mac.
It’s time to finally create something! To quick start open a terminal and run the command:
docker run --name postgres -e POSTGRES_PASSWORD=your_pass -p 5438:5432 -d postgresWhat we did? Calling this command
- pulls the
postgresDocker image from Docker Hub, - sets the
POSTGRES_PASSWORDenvironment variable value to your_pass, - names (
--name) the Docker container to bepostgres, - maps container’s internal 5432 to external 5438 port (it is good practice to set the same ports, however on my computer port 5432 is already in use),
- enables to run the Docker container in the background (-d)
Now you can connect to the database using the selected database client (I prefer DataGrip or Valentina Studio) or even with the console. Now we move on to the design of the database. Everything will be done in one schema, so we don’t need to create additional schemas. We will put all the necessary tables, triggers and other functions into the public schema.
At the first stage, we will put the data from the CSV file into the database. To do this, we first need to establish specific tables in the database. Below are the tables which I’ve added.
Our database model begins with the CLUB table, which contains basic information including name, id, email, phone etc. It also has a field for the user to indicate their preference for what type of communication should be used to contact them (club can choose type of communication – email or phone).
create table club
(
club_id serial
constraint club_pk
primary key,
name varchar(200) not null,
city varchar(100) not null,
email_address varchar(100),
phone char(10),
is_notified char(1) not null,
year_of_foundation int
);Each club has relation to the account table. Club table has many-to-many relationships with the Account table, because Club could have many different Accounts while each Account could have many Clubs. As you can see, the Account table has only few fields – id, current balance and the timestamp of the last executed statement.
create table account
(
account_id serial,
balance float not null,
last_statement_timestamp timestamp
);
create unique index account_account_id_uindex
on account (account_id);
alter table account
add constraint account_pk
primary key (account_id);create table club_account
(
club_club_id int not null
constraint club_account_pk
primary key
constraint club_account_club_club_id_fk
references club,
account_account_id int not null
constraint club_account_account_account_id_fk
references account
);The last table we need is the Transaction table. It contains fields describing the most important parameters for each transaction. It’s simply to understand that each Account table has a one-to-many relationships with the Transaction table.
create table transaction
(
transaction_id serial,
account_id int not null
constraint transaction_pk
primary key
constraint transaction_account_account_id_fk
references account,
credit float,
debit float,
creation_timestamp timestamp not null
);
create unique index transaction_transaction_id_uindex
on transaction (transaction_id);In order to import the club data from the CSV file, we need to understand the specific file format which will be containing all information. In that case, the file consists of three record types:
– for updating name and foundation year fields,
– for updating address fields,
– for updating club communication mechanism.
Each subsequent record should consist of the same number of attributes belonging to a given table. Our task will be to properly transform the received data so that the database can be properly updated. It’s important to note that it is expected that the specific club exist in the database prior to the update record coming through.
Each record type will be indicated in first parameter in the record. Let’s look at each of the three cases:
Record type for updating name and year of foundation:
- Record type – this always be 1 for a record type 1,
- Club ID – this is id of the club record, which will be updated,
- Name – the name of club which should be updated in database (if blank, no update for year of foundation should be done)
- Year of foundation – year of foundation club which should be updated in database (if blank, no update for year of foundation should be done)
Record type for updating address:
- Record type – this always be 2 for a record type 2,
- Club ID – this is id of the club record, which will be updated,
- Address 1 – The first line of the address to be updated (if blank, no update for address should be done),
- Address 2 – The optional second line of the address to be updated (if blank, no update for address should be done),
- City – the city of the club (if blank, no update should be done)
- State – the state of the club (if blank, no update should be done)
- Postal code – postal code of the club (if blank, no update should be done)
Record type for updating club communication mechanism:
- Record type – this always be 3 for a record type 3,
- Club ID – this is id of the club record, which will be updated,
- Email address – the email address to update (if blank, no update should be done),
- Phone – the phone number to update (if blank, no update should be done),
- Notification option – the notification preference (if blank, no update should be done).
Now let’s prepare the initial two files. The first one will contain the basic data that we want to put in our still empty database. All data will be saved in the database using SQL commands.
INSERT INTO club(name, address, email_address, phone, is_notified, year_of_foundation)
VALUES
('Manchester City', '83 Ducie St, Manchester M1 2JQ', 'manchester_city@gmail.com', '855100432', 'M', 1922),
('Paris Saint Germain', '24, Rue du Commandant-Guilbaud 75016 Paris', 'psg@gmail.com', '155101132', 'M', 1924),
('Real Madrid', 'Avenida de Concha Espina 1 Madrid', 'real@yahoo.com', '840177901', 'P', 1899),
('Legia Warszawa', 'Łazienkowska 3, 00-449 Warszawa', 'legia@interia.pl', '589101655', 'M', 1924),
('Czarni Deblin', 'Pułku Piechoty, 08-530 Dęblin', 'czarni@wp.pl', '732011854', 'P', 1931);
INSERT INTO account(balance, last_statement_timestamp)
VALUES
(100000000, '2021-06-22 19:10:25-01'),
(250000000, '2021-10-01 06:50:42-02'),
(110000000, '2020-02-10 11:30:14-07'),
(250000000, '2021-10-01 12:20:11-06'),
(1950000, '2016-11-15 12:41:11-02'),
(999000, '2019-08-22 14:41:21-06'),
(50000, '2018-04-04 21:41:25-01');
INSERT INTO club_account(club_club_id, account_account_id)
VALUES
(1, 1),
(2, 2),
(3, 4),
(1, 3),
(4, 5),
(4, 6),
(5, 7),
(4, 7);
The second file will be in CSV format. This file will contain the records formatted in accordance with the above assumptions.
2,2,,,Paris,,11111
2,2,Rue du Commandant-Guilbaud,,Paris,,41013
3,1,,,,316-510-9138,P
3,4,legiawawa@google.com,785-790-7373,P
1,3,Real Madrid C.F,1902Even before implementing the main code of our application, we need to configure the database connection to our application. We will do this by using the very popular syntax inside the application.properties file, which should be in the resources folder. Remember that the data must match the values provided when creating the database!
spring.datasource.driverClassName=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://localhost:5438/postgres
spring.datasource.username=postgres
spring.datasource.password=postgres
spring.batch.initialize-schema=alwaysTo process file, we’ll begin by defining the job and its first step. First we will create a class responsible for the configuration part. The basic version is shown in the code snippet below.
@Configuration
public class ImportDataJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public ImportDataJobConfiguration(JobBuilderFactory jobBuilderFactory, StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job importClubDataJob() throws Exception {
return this.jobBuilderFactory
.get("importClubDataJob")
.start(importClubUpdates())
.build();
}
@Bean
public Step importClubDataUpdatesStep() throws Exception {
return this.stepBuilderFactory
.get("importClubUpdates")
.<ClubUpdate, ClubUpdate>chunk(100)
.reader(clubDataUpdateItemReader(null))
.processor(clubDataValidatingItemProcessor(null))
.writer(clubDataUpdateItemWriter())
}
}We begin by defining a Spring Configuration class (via the @Configuration) annotation. Then two dependencies of the basic elements of this class are drawn – we import two factories: JobBuilderFactory and StepBuilderFactory. If you cannot find these dependencies (e.g. the compiler signals an error) then make sure that you have added @EnableBatchProcessing annotation to the main class. With the builders wired in, we can define our Job and Step.
Now I will briefly describe what I did for these elements. We’ve created step importClubDataUpdatesStep using StepBuilderFactory to get a StepBuilder which is configured for chunk-based processing. As the name suggests, this approach performs actions over chunks of data. That is, instead of reading, processing and writing all the lines at once, it’ll read, process and write a fixed amount of records (chunk) at a time. This step will use three new components, which will use the elements we are about to create – ItemReader called clubDataUpdateItemReader, ItemProcessor called clubDataValidatingItemProcessor and ItemWriter called clubDataUpdateItemWriter. The built Step function will be called during each process that Job starts – we put this step inside a job importClubDataJob().
We have the skeleton of the first process created. Now we have to get down to a little lower level of abstraction and implement the functionality of each of these methods. The ItemReader in this step is a FlatFileItemReader. We use here a special builder FlatFileItemReaderBuilder for preparing reader method. In the code fragment below I configured a name of item, resource, line tokenizer which parses all records and a FileSetMapper for mapping.
@Bean
@StepScope
public ItemReader<? extends ClubUpdate> clubDataUpdateItemReader(@Value("#{jobParameters['clubData']}") Resource inputFile)
throws Exception {
return new FlatFileItemReaderBuilder<ClubUpdate>()
.name("clubDataUpdateItemReader")
.resource(inputFile)
.lineTokenizer(clubDataUpdatesLineTokenizer())
.fieldSetMapper(clubDataUpdateFieldSetMapper())
.build();
}To fetch a file containing new data, we use the information provided by in the job parameters (there I added a file name). As you can see, we defined ItemReader using functions that we don’t have yet. Now is the time to create them. We need to define the LineTokenizer and FieldSetMapper. We use composition to create a composite that delegates to the correct LineTokenizer based on a pattern for each file. Spring Batch provides the PatternMatchingCompositeLineTokenizer for this very use case. It requires that you create a Map. The String in each Map entry defines a pattern the record must match in order to use that LineTokenizer.
@Bean
public LineTokenizer clubDataUpdatesLineTokenizer() throws Exception {
DelimitedLineTokenizer recordTypeOne = new DelimitedLineTokenizer();
recordTypeOne.setNames("recordId", "clubId", "name", "yearOfFoundation");
recordTypeOne.afterPropertiesSet();
DelimitedLineTokenizer recordTypeTwo = new DelimitedLineTokenizer();
recordTypeTwo.setNames("recordId", "clubId", "address1", "address2", "city", "state", "postalCode");
recordTypeTwo.afterPropertiesSet();
DelimitedLineTokenizer recordTypeThree = new DelimitedLineTokenizer();
recordTypeThree.setNames("recordId", "clubId", "emailAddress", "phone", "notification");
recordTypeThree.afterPropertiesSet();
Map<String, LineTokenizer> tokenizerMap = new HashMap<>(3);
tokenizerMap.put("1*", recordTypeOne);
tokenizerMap.put("2*", recordTypeTwo);
tokenizerMap.put("3*", recordTypeThree);
PatternMatchingCompositeLineTokenizer tokenizer = new PatternMatchingCompositeLineTokenizer();
tokenizer.setTokenizers(tokenizerMap);
return tokenizer;
}After reading this file, we need to map all data from records to a domain object. Firstly, we will create main domain object that has already been called in earlier code snippets. I use different domain objects for each of the three record types – ClubDataBaseUpdate, ClubDataAddressUpdate, ClubDataContactUpdate. All three elements share a common element – clubId. Therefore, we will try to make a more generic version of our classes. I also added two annotations @Getter and @Setter. This significantly reduces the amount of code. If you want to use it too, don’t forget to add the Lombok dependencies to the pom.xml file.
@Getter
@Setter
public class ClubDataUpdate {
protected final long clubId;
public ClubDataUpdate(long clubId) {
this.clubId = clubId;
}
}@Getter
@Setter
public class ClubDataBaseUpdate extends ClubDataUpdate {
private final String name;
private final int yearOfFoundation;
public ClubDataBaseUpdate(long clubId, String name, int yearOfFoundation) {
super(clubId);
this.name = name;
this.yearOfFoundation = yearOfFoundation;
}
}@Getter
@Setter
public class ClubDataAddressUpdate extends ClubDataUpdate {
private final String address1;
private final String address2;
private final String city;
private final String state;
private final String postalCode;
public ClubDataAddressUpdate(final long clubId, final String address1, final String address2,
final String city, final String state, final String postalCode) {
super(clubId);
this.address1 = StringUtils.hasText(address1) ? address1 : null;
this.address2 = StringUtils.hasText(address2) ? address2 : null;
this.city = StringUtils.hasText(city) ? city : null;
this.state = StringUtils.hasText(state) ? state : null;
this.postalCode = StringUtils.hasText(postalCode) ? postalCode : null;
}
}@Getter
@Setter
public class ClubDataContactUpdate extends ClubDataUpdate {
private final String emailAddress;
private final String phone;
private final String notification;
public ClubDataContactUpdate(final long clubId, String emailAddress, String phone, String notification) {
super(clubId);
this.emailAddress = StringUtils.hasText(emailAddress) ? emailAddress : null;
this.phone = StringUtils.hasText(phone) ? phone : null;
this.notification = StringUtils.hasText(notification) ? notification : null;
}
}
In order to determine which object to return, we need a FieldSetMapper that will create and return the
right domain object based on the record type. Like everything so far, we will now implement a method in the configuration class that will be used to map records to our model. To present all possible types in one method, I used a switch function and a lambda expression.
@Bean
public FieldSetMapper<ClubDataUpdate> clubDataUpdateFieldSetMapper() {
return fieldSet -> {
switch (fieldSet.readInt("recordId")) {
case 1:
return new ClubDataBaseUpdate(
fieldSet.readLong("clubId"),
fieldSet.readString("name"),
fieldSet.readInt("yearOfFoundation"));
case 2:
return new ClubDataAddressUpdate(
fieldSet.readLong("clubId"),
fieldSet.readString("address1"),
fieldSet.readString("address2"),
fieldSet.readString("city"),
fieldSet.readString("state"),
fieldSet.readString("postalCode"));
case 3:
return new ClubDataContactUpdate(
fieldSet.readLong("clubId"),
fieldSet.readString("emailAddress"),
fieldSet.readString("phone"),
fieldSet.readString("notification"));
default:
throw new IllegalArgumentException("Invalid record type was found: " + fieldSet.readInt("recordId"));
}
};
}Reading CSV file is only the first part of the process of applying the club data updates. The goal of this step is
to get the data into your database. To do that, we need to first validate that each record actually has a valid
club id. To check all the data, we will implement the validation logic inside the ItemProcessor method called clubDataValidatingItemProcessor.
The intent of this component will be to look up the club id in the ClubDataUpdate object it receives. If it exists in the database, we’ll let the record through. If it does not exist, we’ll filter those records out. To create such a function, we will use validation methods issued by Spring Batch. The method will use the Validator class embedded in the Spring Batch library. If the issued function during record processing, does not find such a record in the database that matches the given clubId, an ValidationException will be thrown.
In order to increase the transparency of the whole project, a method dealing with data validation will be created in a new class which we will call ClubDataItemValidator.
@Component
public class ClubDataItemValidator implements Validator<ClubDataUpdate> {
private final NamedParameterJdbcTemplate jdbcTemplate;
private static final String FIND_CLUB_BY_ID = "SELECT count(*) FROM club WHERE club_id = :id";
public ClubDataItemValidator(DataSource dataSource) {
this.jdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
@Override
public void validate(ClubDataUpdate clubDataUpdate) throws ValidationException {
Map<String, Long> map = Collections.singletonMap("id", clubDataUpdate.getClubId());
Long count = jdbcTemplate.queryForObject(FIND_CLUB_BY_ID, map, Long.class);
if (count == 0) {
throw new ValidationException(String.format("Club with id %s has not found in DB", clubDataUpdate.getClubId()));
}
}
}We can put the implemented validator inside the clubDataValidatingItemProcessor, which will be called directly from our importClubUpdatesStep function.
@Bean
public ItemProcessor<? super ClubDataUpdate, ? extends ClubDataUpdate> clubDataValidatingItemProcessor(
ClubDataItemValidator validator) {
ValidatingItemProcessor<ClubDataUpdate> clubDataUpdateValidatingItemProcessor = new ValidatingItemProcessor<>(validator);
clubDataUpdateValidatingItemProcessor.setFilter(true);
return clubDataUpdateValidatingItemProcessor;
}The last element of this first three-part game with the batch process is updating the data directly in the database. Our functions should respond appropriately to the given values depending on the type of process (one of these three types of data updates). For this reason, you will need to build three different ItemWriter components that will be managed by the parent function. This function managing the selection of these items will be implemented using ClassifierCompositeItemWriter. In fact, all three ItemWriter methods will be similar to each other. The main difference between them will be the SQL procedures that will have to import the data to the appropriate places in the database. Below I’ve added examples of how to implement these three methods:
@Bean
public JdbcBatchItemWriter<ClubDataUpdate> clubDataBaseUpdateJdbcBatchItemWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<ClubDataUpdate>()
.beanMapped()
.sql("UPDATE club " +
"SET name = COALESCE(:name, name), " +
"year_of_foundation = COALESCE(:yearOfFoundation, year_of_foundation) " +
"WHERE club_id = :clubId")
.dataSource(dataSource)
.build();
}
@Bean
public JdbcBatchItemWriter<ClubDataUpdate> clubDataAddressUpdateJdbcBatchItemWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<ClubDataUpdate>()
.beanMapped()
.sql("UPDATE club " +
"SET address = COALESCE(:address1, address), " +
"WHERE club_id = :clubId")
.dataSource(dataSource)
.build();
}
@Bean
public JdbcBatchItemWriter<ClubDataUpdate> clubDataContactUpdateJdbcBatchItemWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<ClubDataUpdate>()
.beanMapped()
.sql("UPDATE club " +
"SET email_address = COALESCE(:emailAddress, email_address), " +
"phone = COALESCE(:phone, phone), " +
"is_notified = COALESCE(:notification, is_notified) " +
"WHERE club_id = :clubId")
.dataSource(dataSource)
.build();
}Each of added ItemWriter methods should do similar process. They just update different columns in tables with the specific new values. I’ve also added COALESCE procedure inside SQL statement cuz I want to update the values that the input file provided. If we have already implemented individual components for updating data in the database, now we can add a method responsible for choosing one of these methods appropriate for a given case. To do this, we will create a new method that will implement the functionalities provided in the Classifier interface. This interface is also available in the Spring Batch library.
public class ClubDataUpdateClassifier implements Classifier<ClubDataUpdate, ItemWriter<? super ClubDataUpdate>> {
private final JdbcBatchItemWriter<ClubDataUpdate> recordTypeOneItemWriter;
private final JdbcBatchItemWriter<ClubDataUpdate> recordTypeTwoItemWriter;
private final JdbcBatchItemWriter<ClubDataUpdate> recordTypeThreeItemWriter;
public ClubDataUpdateClassifier(JdbcBatchItemWriter<ClubDataUpdate> recordTypeOneItemWriter,
JdbcBatchItemWriter<ClubDataUpdate> recordTypeTwoItemWriter,
JdbcBatchItemWriter<ClubDataUpdate> recordTypeThreeItemWriter) {
this.recordTypeOneItemWriter = recordTypeOneItemWriter;
this.recordTypeTwoItemWriter = recordTypeTwoItemWriter;
this.recordTypeThreeItemWriter = recordTypeThreeItemWriter;
}
@Override
public ItemWriter<? super ClubDataUpdate> classify(ClubDataUpdate classifiable) {
if (classifiable instanceof ClubDataBaseUpdate) {
return recordTypeOneItemWriter;
} else if (classifiable instanceof ClubDataAddressUpdate) {
return recordTypeTwoItemWriter;
} else if (classifiable instanceof ClubDataContactUpdate) {
return recordTypeThreeItemWriter;
} else {
throw new IllegalArgumentException(String.format("Invalid type: %s", classifiable.getClass().getCanonicalName()));
}
}
}Individual ItemWriter methods are already ready for each type of operation. The method for selecting the appropriate type of operation is also done. So we can now move our solutions to the main component responsible for updating data so now we go to clubDataUpdateItemWriter.
@Bean
public ItemWriter<? super ClubDataUpdate> clubDataUpdateItemWriter() {
ClubDataUpdateClassifier classifier = new ClubDataUpdateClassifier(
clubDataBaseUpdateJdbcBatchItemWriter(null),
clubDataAddressUpdateJdbcBatchItemWriter(null),
clubDataContactUpdateJdbcBatchItemWriter(null));
ClassifierCompositeItemWriter<ClubDataUpdate> compositeItemWriter = new ClassifierCompositeItemWriter<>();
compositeItemWriter.setClassifier(classifier);
return compositeItemWriter;
}With all of those classes, methods and properties configured, you can build your project from the command line via simple command ./mvnw clean install. Once that is complete, from the target directory of our project, we can run it via the command java -jar SoccerBank-0.0.1-SNAPSHOT.jar clubData=<path to file with club data>. With that, you should be able to validate the data has been correctly applied to the club table. Alternatively, you can run an application written by you in a much simpler way using the compiler built into the tool you are using.
If you’ve been able to update the database based on the imported file, it’s very good. I would like to tell you about one more thing – if you want to re-import the data, you will get the following error:
A job instance already exists and is complete for parameters={clubData=clubDataFile.csv}. If you want to run this job again, change the parameters.It is related to the parameters of this batch process. To be able to perform this operation again, you will have to change the name of the file, which is given in the form of a parameter or add a properly configured JobLauncher, which will add an appropriate variable on the fly to keep these parameter sets unique. More information about this issue and how to fix it can be found here.
If we have already prepared our data, we can try to handle several transactions made between clubs. Suppose the transfer season is about to begin and clubs start buying and selling their players. For this project, the full list of transactions carried out will be kept in an XML file (I changed the file format to show you different ways of dealing with data). In this part of the guide, we will try to import the changes contained in the file to the database and process the data accordingly.
The transaction file begins with a transactions element that wraps all of the individual transaction elements. Each transaction chunk represents a single bank transaction and will result in an item in our batch job. What was included in the file can now be mapped to a domain object inside the application.
@XmlRootElement(name = "transaction")
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Setter
public class Transaction {
private long transactionId;
private long accountId;
private String description;
private BigDecimal credit;
private BigDecimal debit;
private Date timestamp;
@XmlJavaTypeAdapter(JaxbDateSerializer.class)
public void setTimestamp(Date timestamp) {
this.timestamp = timestamp;
}
public BigDecimal getTransactionAmount() {
if (credit != null) {
if (debit != null) {
return credit.add(debit);
}
else {
return credit;
}
} else return Objects.requireNonNullElseGet(debit, () -> new BigDecimal(0));
}
}As you can see, in our Transaction class we have fields that map directly to the XML chunks (what we’ve added in xml file). The three significant items on this class are the @XmlRootElement, @XmlJavaTypeAdapter and the additional method getTransactionAmount(). The @XmlRootElement is a JAX-B annotation that defines what the root tag is for that domain object. In our case, it is the tag transaction. The @XmlJavaTypeAdapter is used on the setter for the timestamp field because JAX-B doesn’t have a nice and simple way to handle the conversion from a
String to a java.util.Date. Because of that, we need to provide a bit of code that JAX-B will use to do that conversion which is the JaxbDateSerializer. As usual, to minimize the amount of boilerplate code, I added the lombok annotation – these are related to constructor creation and the get and set methods.
public class JaxbDateSerializer extends XmlAdapter<String, Date> {
private SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
@Override
public Date unmarshal(String date) throws Exception {
return dateFormat.parse(date);
}
@Override
public String marshal(Date date) throws Exception {
return dateFormat.format(date);
}
}This JaxbDateSerializer class will help us transform a date value (from string to date and from date to string). In addition, the previously mentioned getTransactionAmount() method, which is embedded inside the Transaction class, will help us calculate the final amounts that we operate during the transaction.
Let’s start the importing of our bank transactions by configuring the Step and adding it to our Job. We will use StaxEventItemReader to read XML files. In this step, we will compose two individual processes – reading first and then writing. ItemReader was implemented using a StaxEventItemReaderBuilder. While building, you should provide the name of the object, the location of the XML file placed in the parameters, the type of the main domain entity in the XML file and a reference to the unmarshaller.
@Bean
@StepScope
public StaxEventItemReader<Transaction> transactionItemReader(
@Value("#{jobParameters['transactionFile']}") Resource transactionFile) {
Jaxb2Marshaller unmarshaller = new Jaxb2Marshaller();
unmarshaller.setClassesToBeBound(Transaction.class);
return new StaxEventItemReaderBuilder<Transaction>()
.name("transactionItemReader")
.resource(transactionFile)
.addFragmentRootElements("transaction")
.unmarshaller(unmarshaller)
.build();
}Now that we have the prepared part of the code responsible for reading the file, now we can start saving transactions. We will create a new ItemWriter method called transactionItemWriter(). Inside this function I have built a simple SQL query that we will use to add new records in the database.
@Bean
public JdbcBatchItemWriter<Transaction> transactionItemWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Transaction>()
.dataSource(dataSource)
.sql("INSERT INTO transaction(transaction_id, account_id, description, credit, debit, creation_timestamp) " +
"VALUES (:transactionId, :accountId, :description, :credit, :debit, :creationTimestamp)")
.beanMapped()
.build();
}If we have both elements ready, we can build the next step and insert it into the previously prepared Job.
@Bean
public Step importTransactionsStep() {
return this.stepBuilderFactory
.get("importTransactionsStep")
.<Transaction, Transaction>chunk(100)
.reader(transactionItemReader(null))
.writer(transactionItemWriter(null))
.build();
}@Bean
public Job importClubDataJob() throws Exception {
return this.jobBuilderFactory
.get("importClubDataJob")
.start(importClubUpdatesStep())
.next(importTransactionsStep())
.incrementer(new RunIdIncrementer())
.build();
}Two parts ready, so let’s try to start our machine a second time. With the ItemReader and ItemWriter configured, we can build our job via ./mvnw clean install and run it with the same command as last time plus our new input file
parameter: java -jar SoccerBank-0.0.1-SNAPSHOT.jar clubData=<path to file with club data> transactionFile=<path to file with transactions>. After our job’s successful run, we can validate that the values in the transaction XML file got into the transaction table in our database.
Job: [SimpleJob: [name=importClubDataJob]] completed with the following parameters: [{clubData=clubDataFile.csv, transactionFile=transactions.xml, clubDataFile=clubDataFile.csv, run.id=5}] and the following status: [COMPLETED] in 294msWhen we have already embedded existing clubs and accounts in the database, and the transactions are placed in the database, the time has come to settle contractors on the basis of transferred money. Now we will deal with checking the amount of money and taking care of the proper balance and settlement of accounts.
The next step in the entire batch operation is complete. So we can add two subprocesses to this step and then incorporate it into the main batch job.
@Bean
public Job importClubDataJob() throws Exception {
return this.jobBuilderFactory
.get("importClubDataJob")
.start(importClubUpdatesStep())
.next(importTransactionsStep())
.next(applyClubTransactionStep())
.incrementer(new RunIdIncrementer())
.build();
}@Bean
public Step applyClubTransactionsStep() {
return stepBuilderFactory
.get("applyClubTransactionsStep")
.<Transaction, Transaction>chunk(100)
.reader(applyClubTransactionReader(null))
.writer(applyClubTransactionWriter(null))
.build();
}The Step is created using the builders configured to read and write Transaction domain objects with a chunk size of 100. As you can see, we still lack two methods that we should implement as spring beans (so that they can be called from anywhere). In this section, we will deal with the implementation of the applyClubTransactionReader and applyClubTransactionWriter methods.
We first look at the method to read values, now we no longer need external files. We will fetch everything directly from the database (this is why we imported the data from files into the database in the previous stage). Reading the transaction data from the database table we just imported it into is simple thanks to the JdbcCursorItemReader. To use that reader, all we need to configure is the name (for restartability), a DataSource, a SQL statement, and in our case a RowMapper implementation. We’ll use a lambda expression for that. That really is all that’s needed to read the Transaction data.
@Bean
public JdbcCursorItemReader<Transaction> applyClubTransactionReader(DataSource dataSource) {
return new JdbcCursorItemReaderBuilder<Transaction>()
.name("applyClubTransactionReader")
.dataSource(dataSource)
.sql("SELECT transaction_id, account_id, description, credit, debit, creation_timestamp " +
"FROM transaction ORDER BY creation_timestamp")
.rowMapper((resultSet, i) ->
new Transaction(
resultSet.getLong("transaction_id"),
resultSet.getLong("account_id"),
resultSet.getString("description"),
resultSet.getBigDecimal("credit"),
resultSet.getBigDecimal("debit"),
resultSet.getTimestamp("creation_timestamp")))
.build();
}If we have read what we need, now we can take up the most interesting task – we will now introduce changes to our database based on transactions made by the clubs.
To save the changes to the database, I configured ItemWriter with JdbcBatchItemWriter. During the initialization of this method, the DataSource and the SQL statement were declared. This SQL query is responsible for adding the transaction amount to the current balance and identifies that the parameters in our SQL query can be filled by calling the seed property.
@Bean
public JdbcBatchItemWriter applyClubTransactionWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Transaction>()
.dataSource(dataSource)
.sql("UPDATE account SET balance = balance + :transactionAmount WHERE account_id = accountId")
.beanMapped()
.assertUpdates(false)
.build();
}So you can once again build our jar with the project and try to run the project. This time, our data collected from transactions should result in a change in the value of the amounts available on the clubs’ accounts. Using the same commands we can validate that our the newest step works correctly. First, build the package via command /mvnw clean install and run it with the same command as last time java -jar SoccerBank-0.0.1-SNAPSHOT.jar clubData=<path to file with club data> transactionFile=<path to file with transactions>
Job: [SimpleJob: [name=importClubDataJob]] completed with the following parameters: [{clubData=clubDataFile.csv, transactionFile=transactions.xml, clubDataFile=clubDataFile.csv, run.id=12}] and the following status: [COMPLETED] in 311ms
The end goal of this batch job is to generate a statement for each club with a summary of their account. Large companies and large corporations always carry out thousands of operations and transfers every day, so it is always worth storing it somewhere. Thanks to this, in the event of any uncertainty, employees can check the history of operations. To collect this data, we will need a new domain existence. We will create a Statement class responsible for maintaining relations between the two most important entities – club and account.
@Getter
@Setter
@NoArgsConstructor
public class Statement {
private Club club;
private List<Account> accounts = new ArrayList<>();
public Statement(Club club, List<Account> accounts) {
this.club = club;
this.accounts.addAll(accounts);
}
}This class has relationships to Club and Account classes, so we need to create them. We will create both object domains with all necessary attributes, which also exist in database tables.
@Getter
@Setter
public class Club {
private final long id;
private final String name;
private final String address;
private final String emailAddress;
private final String phone;
private final String notification;
private final int yearOfFoundation;
public Club(long id, String name, String address, String emailAddress, String phone, String notification, int yearOfFoundation) {
this.id = id;
this.name = name;
this.address = address;
this.emailAddress = emailAddress;
this.phone = phone;
this.notification = notification;
this.yearOfFoundation = yearOfFoundation;
}
}@Getter
@Setter
public class Account {
private final long id;
private final BigDecimal balance;
private final Date lastStatementTimestamp;
private final List<Transaction> transactions = new ArrayList<>();
public Account(long id, BigDecimal balance, Date lastStatementTimestamp) {
this.id = id;
this.balance = balance;
this.lastStatementTimestamp = lastStatementTimestamp;
}
}While our domain object consists of all of the components for our statement, our reader won’t populate them all. For this step, we will use what’s called the driving query pattern. This means our ItemReader will read just the basics (the Club in this case). The ItemProcessor will enrich the Statement object with the account information before going to the ItemWriter for the final generation of the statement.
We already have all domain entities created. So we can take care of the instance of the batch process. First, we will add another step to our main Job method and then implement it.
@Bean
public Job importClubDataJob() throws Exception {
return this.jobBuilderFactory
.get("importClubDataJob")
.start(importClubUpdatesStep())
.next(importTransactionsStep())
.next(applyClubTransactionsStep())
.next(generateStatementsStep())
.incrementer(new RunIdIncrementer())
.build();
}@Bean
public Step generateStatements(AccountItemProcessor itemProcessor) {
return this.stepBuilderFactory
.get("generateStatements")
.<Statement, Statement>chunk(1)
.reader(statementItemReader(null))
.processor(itemProcessor)
.writer(statementItemWriter(null))
.build();
}The final step in our job will be generateStatementsStep. It consists of a simple ItemReader, an ItemProcessor, and an ItemWriter. You’ll notice that the chunk size is one for our final step. The reason for this is that we want a single file per statement. To do that, we’ll use the MultiResourceItemWriter. This, however, only rotates files once per chunk. If we want one file per item, our chunk size then needs to be 1.
By default, at the beginning of this step we will take care of getting the values we are interested in. Also this time we will use the JdbcCursorItemReader class for this.
@Bean
public JdbcCursorItemReader statementItemReader(DataSource dataSource) {
return new JdbcCursorItemReaderBuilder<Statement>()
.name("statementItemReader")
.dataSource(dataSource)
.sql("SELECT * FROM club")
.rowMapper((resultSet, i) -> {
Club club = Club.builder()
.id(resultSet.getLong("club_id"))
.name(resultSet.getString("name"))
.address(resultSet.getString("address"))
.emailAddress(resultSet.getString("email_address"))
.phone(resultSet.getString("phone"))
.notification(resultSet.getString("is_notified"))
.yearOfFoundation(resultSet.getInt("year_of_foundation"))
.build();
return new Statement(club);
})
.build();
}The generated reports will contain data from more than one table, so using the RowMapper element used so far is not enough here.We’ll use a ResultSetExtractor because the query we’ll be running results in a parent child relationship with one account having many transactions. We will place all of this processing in a method that is between the traditional read and write operations. We will place the processing function in a separate class, so that it is much easier to manage, and moreover, we already have a fairly extensive batch configuration class. In this way, we will implement the previously declared AccountItemProcessor class. This ItemProcessor runs a query to find all the accounts and their transactions for a specified Club.
@Component
public class AccountItemProcessor implements ItemProcessor<Statement, Statement> {
private final JdbcTemplate jdbcTemplate;
public AccountItemProcessor(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public Statement process(Statement statement) throws Exception {
statement.setAccounts(this.jdbcTemplate
.query(
"SELECT a.account_id, a.balance, a.last_statement_timestamp, " +
"t.transaction_id, t.description, t.credit, t.debit, t.creation_timestamp " +
"FROM account a " +
"LEFT JOIN transaction t ON a.account_id = t.account_id " +
"WHERE a.account_id IN " +
"(SELECT account_account_id FROM club_account WHERE club_club_id = ? " +
"ORDER BY t.creation_timestamp)",
new Object[] {statement.getClub().getId()}, new AccountResultSetExtractor()));
return statement;
}
}We will process information about transactions and related objects downloaded from the database in a separate class. We iterate over the ResultSet building an Account object. If the current Account is null or the account id does not equal the current one, we’ll create a new Account object. Once we have the Account object, for each record that has a transaction, we add a Transaction object. This allows us to build up a list of Account objects that we return to the ItemProcessor which adds them to the Statement item to be written. The last piece of this puzzle is the configuration of the ItemWriter. Saving the best for last, let’s dig into the ItemWriter used for writing the statement files.
public class AccountResultSetExtractor implements ResultSetExtractor<List<Account>> {
private List<Account> accounts = new ArrayList<>();
private Account currentAccount;
@Nullable
@Override
public List<Account> extractData(ResultSet rs) throws SQLException, DataAccessException {
while (rs.next()) {
if (currentAccount == null) {
currentAccount = new Account(
rs.getLong("account_id"),
rs.getBigDecimal("balance"),
rs.getDate("last_statement_date"));
} else if (rs.getLong("account_id") != currentAccount.getId()) {
accounts.add(currentAccount);
currentAccount = new Account(
rs.getLong("account_id"),
rs.getBigDecimal("balance"),
rs.getDate("last_statement_date"));
}
if(StringUtils.hasText(rs.getString("description"))) {
currentAccount.getTransactions().add(new Transaction(
rs.getLong("transaction_id"),
rs.getLong("account_id"),
rs.getString("descritpion"),
rs.getBigDecimal("credit"),
rs.getBigDecimal("debit"),
new Date(rs.getTimestamp("creation_timestamp").getTime())));
}
}
if (currentAccount != null) {
accounts.add(currentAccount);
}
return accounts;
}
}Reports generated by us, instead of being in the database, should go directly to the interested users. Now, in the last phase of our project, we prepare appropriate functions that will create one file for each generated report. We will prepare a permanent scheme into which you can insert dynamically changing data every time. The StatementLineAggregator class will be responsible for data merging.
public class StatementLineAggregator implements LineAggregator<Statement> {
private static final String ADDRESS_LINE = String.format("%121s\n", "Soccer Manager Banking");
private static final String STATEMENT_DATE_LINE = String.format("Club Account Summary %78s ", "Statement Period")
+ "%tD to %tD\n\n";
@Override
public String aggregate(Statement statement) {
StringBuilder output = new StringBuilder();
formatHeader(statement, output);
formatAccount(statement, output);
return output.toString();
}
}The code has been divided into appropriate parts in such a way that each method performs the selected task.
private void formatAccount(Statement statement, StringBuilder output) {
if (!CollectionUtils.isEmpty(statement.getAccounts())) {
for (Account account : statement.getAccounts()) {
output.append(String.format(STATEMENT_DATE_LINE, account.getLastStatementTimestamp(), new Date()));
BigDecimal creditAmount = new BigDecimal(0);
BigDecimal debitAmount = new BigDecimal(0);
for (Transaction transaction : account.getTransactions()) {
if (transaction.getCredit() != null) {
creditAmount = creditAmount.add(transaction.getCredit());
}
if (transaction.getDebit() != null) {
debitAmount = debitAmount.add(transaction.getDebit());
}
output.append(String.format("%tD %-50s %8.2f\n",
transaction.getCreationTimestamp(), transaction.getDescription(), transaction.getTransactionAmount()));
}
output.append(String.format("%80s %14.2f\n", "Total Debit:" , debitAmount));
output.append(String.format("%81s %13.2f\n", "Total Credit:", creditAmount));
output.append(String.format("%76s %18.2f\n\n", "Balance:", account.getBalance()));
}
}
}private void formatHeader(Statement statement, StringBuilder output) {
Club club = statement.getClub();
String clubName = String.format("\n%s", club.getName());
output.append(clubName).append(ADDRESS_LINE.substring(clubName.length()));
}The majority of that code is String.format calls with well-defined expressions. Both methods formatHeader and formatAccount are responsible for formating and appending strings to the final output, which should be inside the file. The last class, which takes care of fetching and appending all data together in one place is StatementHeaderCallback.
It’s time to put all these components together. We wrote quite a lot of code today, so now we should count on some nice final effects. As in the previous cases, the decorated ItemWriter will be responsible for generating the output. First, we will create a generic method that will create the output file for each club separately. However, later we will enrich our class with an additional function that will handle many such reports at once. Thanks to this, it will be possible to perform the full process for more clubs.
@Bean
@StepScope
public MultiResourceItemWriter<Statement> statementItemWriter(
@Value("#{jobParameters['outputDirectory']}") Resource outputDirectory) {
final String ROOT_PATH = "file://home/oskarro/";
ClassPathResource classPathResource = new ClassPathResource(ROOT_PATH + outputDirectory.getFilename());
Resource resource = resourceLoader.getResource(classPathResource.getPath());
return new MultiResourceItemWriterBuilder<Statement>()
.name("statementItemWriter")
.resource(resource)
.itemCountLimitPerResource(1)
.delegate(singleStatementItemWriter())
.build();
}Now we produce end effects. We have to check how it turned out! We can run the application using the same two commands. This time we also need to add the target path where we want to save the output files. So once again, first, build the package via command /mvnw clean install and run it with the same command as last time java -jar SoccerBank-0.0.1-SNAPSHOT.jar clubData=<path to file with club data> transactionFile=<path to file with transactions> outputDirectory=L<path to output directory>. In the target folder, you should get a final file containing the entire schema with all the data for recent transactions.
Club Service Number
(48) 333-8401
Available 24/7
Czarni Deblin Soccer Manager Banking
Your Account Summary Statement Period 04/04/18 to 10/10/21
Total Debit: 0.00
Total Credit: 0.00
Balance: 50000.00 Club Service Number
(48) 333-8401
Available 24/7
Legia Warszawa Soccer Manager Banking
Your Account Summary Statement Period 08/22/19 to 10/10/21
Total Debit: 0.00
Total Credit: 0.00
Balance: 999000.00
Your Account Summary Statement Period 04/04/18 to 10/10/21
Total Debit: 0.00
Total Credit: 0.00
Balance: 50000.00
Your Account Summary Statement Period 11/15/16 to 10/10/21
02/01/21 Improve local area -60111.00
Total Debit: -60111.00
Total Credit: 0.00
Balance: -1055550.00
You can find the full project on my GitHub repository -> click here
The guide was created based on my own knowledge, material from the Spring Batch book and information found on websites and in other guides. The most important sources are below:
- https://spring.io/projects/spring-batch
- https://docs.oracle.com/javase/tutorial/essential/environment/index.html
- https://www.baeldung.com/introduction-to-spring-batch
- https://howtodoinjava.com/spring-batch/
- The Definitive Guide to Spring Batch – Apress Book
Thanks for reading the entire tutorial. If you have any questions or comments – feel free to share them with us in the comment. I will answer everything for sure.
10 maja, 2022, 3:05 am
Very good information. Lucky me I ran across your blog by chance (stumbleupon). I’ve book marked it for later!
29 października, 2022, 6:05 pm
Świetny poradnik! Czy możesz podać link do repozytorium kodu?
29 października, 2022, 6:56 pm
Hej, link do repo można znaleźć na końcu artykułu.
https://github.com/Oskarovsky/SoccerBank
28 grudnia, 2022, 10:05 pm
The best Spring Batch tutorial I’ve seen so far.
Just what I needed for my project. Thank you a lot man